
One goal of Integrate Wappalyzer platform detection (#19) on GitHub is to find a way to use BigQuery as the engine to drive Wappalyzer’s detections. In that thread, I shared an enormous 83 TB query that:
- scans all response bodies and response headers of root documents since we started collecting them in 2016 and
- extracts the pages detected to contain signs of WordPress (or at least the signs of something that depends on WordPress, like a plugin).
The lynchpin of the query is that I converted Wappalyzer’s JSON-based rules into a table on BigQuery: https://bigquery.cloud.google.com/table/httparchive:wappalyzer.apps
Here are the Wappalyzer rules for WordPress:
"WordPress": {
"cats": [
1,
11
],
"js": {
"wp_username": ""
},
"html": [
"<link rel=[\"']stylesheet[\"'] [^>]+wp-(?:content|includes)",
"<link[^>]+s\\d+\\.wp\\.com"
],
"icon": "WordPress.svg",
"implies": [
"PHP",
"MySQL"
],
"meta": {
"generator": "WordPress( [\\d.]+)?\\;version:\\1"
},
"script": "/wp-includes/",
"website": "http://wordpress.org"
}
And their representation on BigQuery:
![]()
{
"meta": [
{
"value": "WordPress( [\\d.]+)?",
"name": "generator"
}
],
"scripts": null,
"headers": [],
"html": [
"<link rel=[\"']stylesheet[\"'] [^>]+wp-(?:content|includes)",
"<link[^>]+s\\d+\\.wp\\.com"
],
"categories": [
"CMS",
"Blogs"
],
"name": "WordPress",
"script": [
"/wp-includes/"
],
"url": null,
"implies": [
"PHP"
]
}
So for example we can run REGEXP_CONTAINS queries using the html regular expressions against 2 year old response bodies.
In the most recent desktop crawl, it directly or indirectly detected WordPress on 199,022 URLs. It directly detected WordPress on 103,328 URLs.
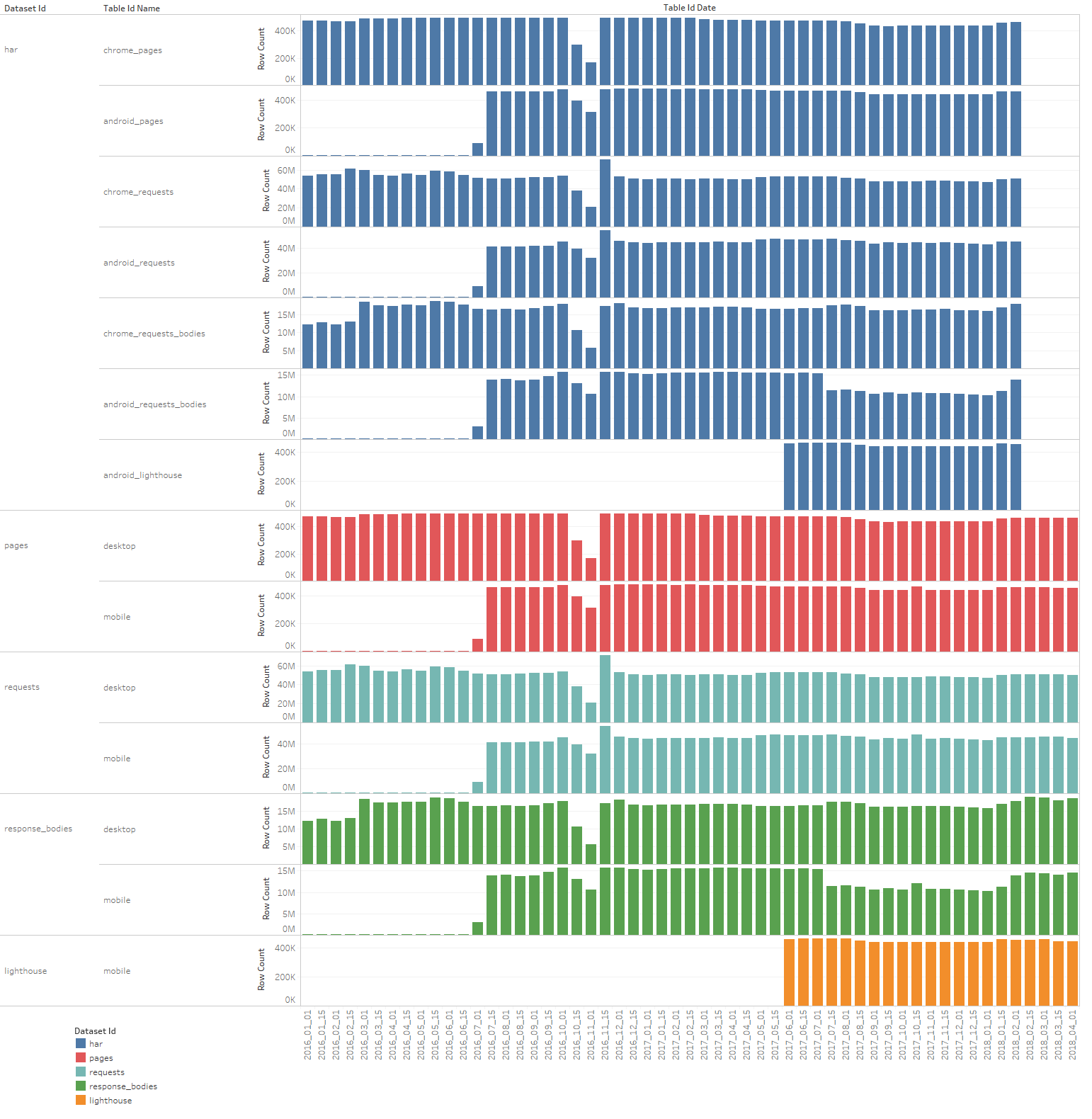
Plotting the detections over time for desktop/mobile:

It’s a bit wonky. Making sense of every dip and spike requires knowing all the pipeline bugs over the years. But the 199,022 figure seems reasonable?? It’s been in that neighborhood for about a year.
Here’s the same thing but only the direct detections:

A few interesting observations:
1/12016 - 5/1/2017 There’s a steady decline for both desktop and mobile. Hard to tell what the cause is.
7/1/2016 Mobile is late to the party.
11/1/2016 Big drop, but recovered. Side effect of a pipeline error?
5/1/2017 Influx of positive detections. Did our crawl artifacts expand coverage to allow for more detections?
5/1/2017 - present Accounting for the big jumps, there still seems to be a decline. And the gap between desktop and mobile is widening.
7/15/2017 Another big spike, but mostly contained to direct detections on desktop. Also on this date implied mobile detections dropped.
2/1/2018 Spike in mobile detections. This looks like a correction of the drop noted above.
3/15/2018 Huge drop, but recovered. Side effect of a pipeline error?
In @paulcalvano’s awesome analysis of the BigQuery metadata, he noted a few anomalies that correlate with some of these. For example, the 7/15/17 drop in mobile detections could be explained by missing data in the android_request_bodies tables.
{kind=link}
Next I’ll be analyzing performance data about the WordPress sites and comparing that to the baseline.