
Remy Sharp wrote this analysis of jQuery based on HTTP Archive data a few days ago on his blog: Is jQuery still relevant?
xposting here to start a discussion on the analysis methodology.
I left a few comments on his post to highlight some pitfalls/nits (pending moderation, so not immediately visible):
1:
The HTTP Archive crawls the top 10,000 web sites from the Alexa top 1,000,000 web sites and exposes all that data in a BigQuery table (or as a downloadable mysql database).
HTTP Archive currently covers 500,000 of the top Alexa 1M. I’ll check the docs ![]()
2:
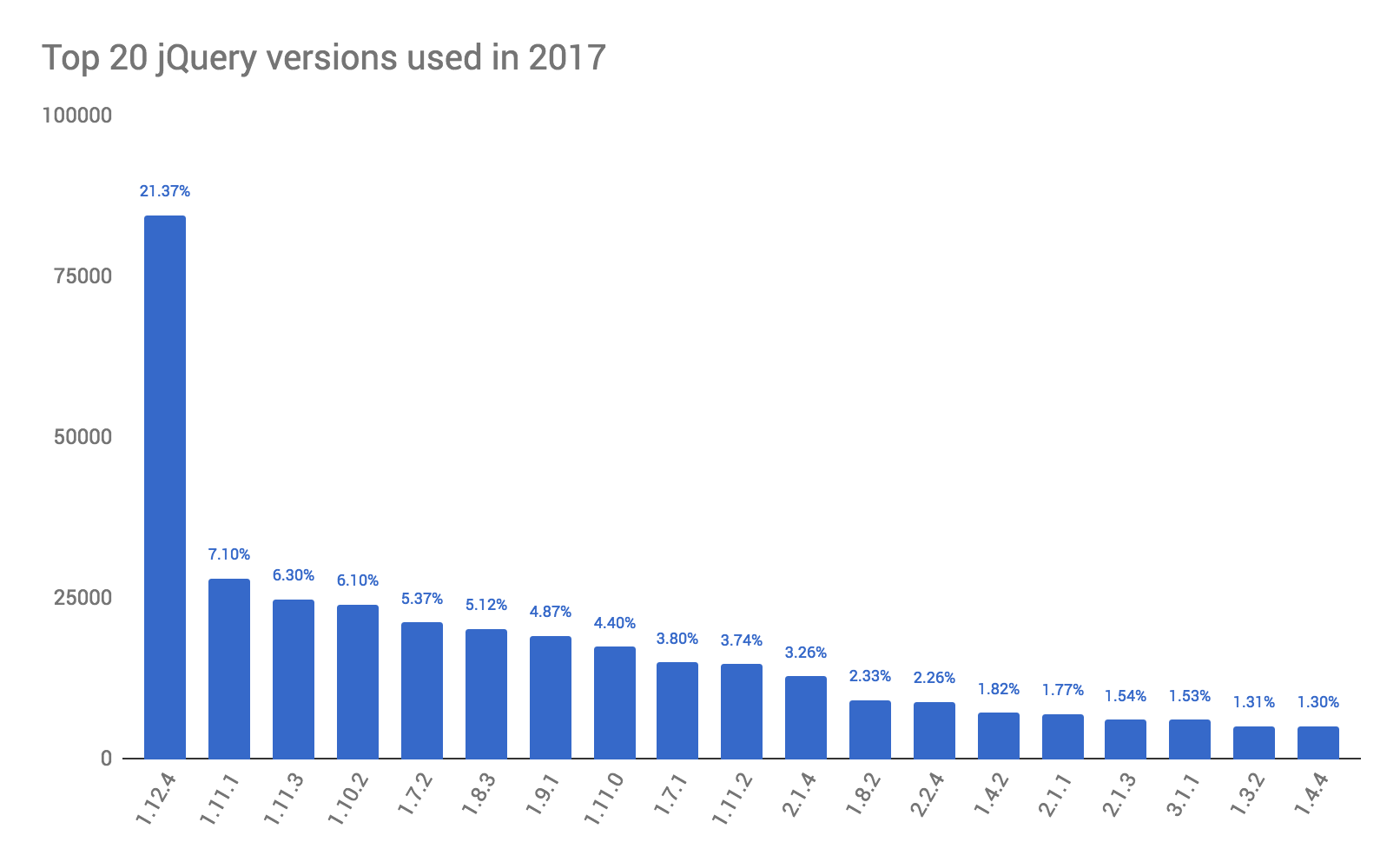
Be careful when looking at the biweekly data and extrapolating annual trends. For example, the “Top 20 jQuery versions used in 2017” analysis only looks at data from the July 1 crawl.
3:
Finally (and this query appears often): how year on year usage changes. I’ve included Angular.JS for contrast. The table looks like the delta between 2016 and 2017 is showing the first drop in usage (by 2%):
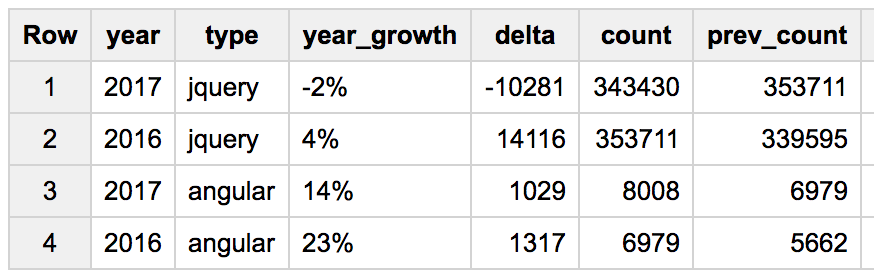
The comparison with Angular is based on network requests that include the library name in the URL. I’d argue that there’s a lot of bias and unreliability in that approach mainly because of JS bundling. Angular users are probably going to be more likely to bundle their JS and omit the library name from the URL.
4:
See also the similar analysis I did in May: JavaScript Library Detection